
Acaba de empezar el PREP 2012. Esta entrada irá actualizándose durante la noche (o bien será la primera de varias entradas).
El PREP es un mecanismo de monitoreo, en tiempo real, del flujo de datos electorales de las casillas conforme llegan a los centros de acopio en las 300 juntas distritales del país. El PREP no es un instrumento de medición que permita hacer pronósticos válidos o confiables toda vez que no está basado en una muestra representativa de casillas, sino en el flujo acumulado, en tiempo real, de las casillas: una especie de censo. Y como este flujo tiene por naturaleza una serie de sesgos, es muy difícil obtener resultados representativos a partir del PREP.
En 2006, con un resultado tan cerrado, muchos se preguntaron: ¿Por qué Calderón estuvo siempre arriba en el PREP, y AMLO durante gran parte del cómputo distrital? ¿Por qué no hubo “cruce” en el PREP y sí lo hubo en el cómputo distrital? Haciendo un análisis de los datos casilla por casilla provistos por el IFE, encontramos una posible respuesta.
En el PREP 2006, FC inició con ventaja, pero esta se redujo conforme llegaron más y más casillas rurales. Sin embargo, su ventaja se estabilizó en alrededor de 1% en la madrugada del lunes 3 de julio. En 2006, hubo 70% de casillas urbanas y 30% no urbanas: Calderón ganó en las primeras y AMLO en las segundas. En las primeras 7 del PREP se procesaron casi todas las casillas urbanas, mientras que las casillas rurales se tardaron un poco más.
Las siguientes gráficas ilustran lo anterior:
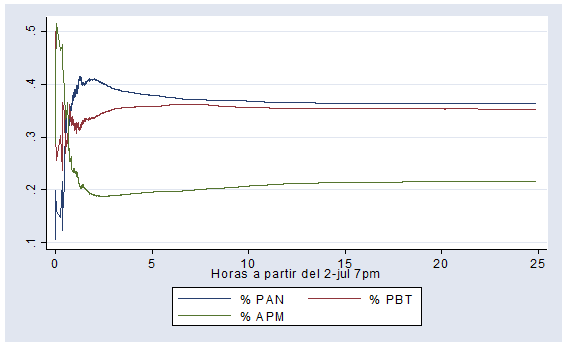
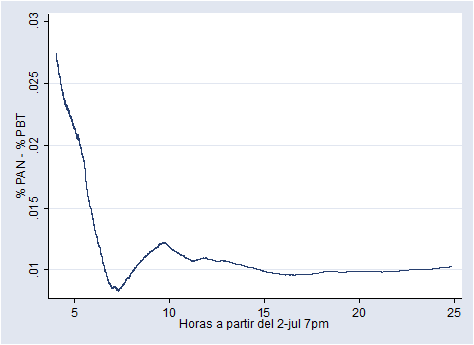
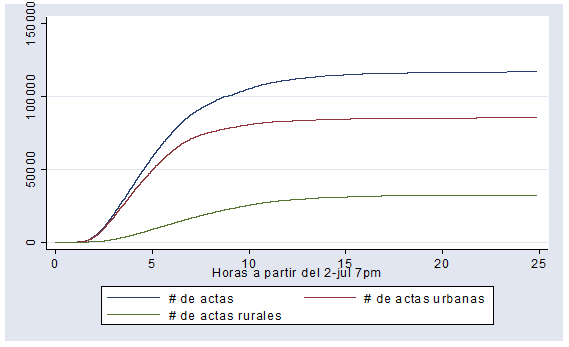
Son las 3 de la mañana y ya circula por ahí que un “científico” encontró un algoritmo en el PREP 2012. ¿Su evidencia? Una correlación de Pearson cercana a 1. Aquí te comparto mi “PREP de mentiritas” (es un archivo en Excel) para que veas por ti mismo que se trata de una mentira.
Materiales relacionados: Análisis estadístico de la elección presidencial de 2006: ¿fraude o errores aleatorios?, Política y Gobierno, volumen temático 2009 – Elecciones en México, págs. 225-243. [Micrositio sobre la elección presidencial 2006.]

Del archivo de Excel:
1) Para ejecutarlo en mi versión hube de cambiar la función a «=randbetween(0,750)» porque la otra no la reconoció.
2) Habiendo hecho esto, ¿por qué es válido dejar completamente aleatorios los números en las tres columnas habida cuenta que la suma total tendría que ser constante? ¿afecta esto a lo de la correlación?
Gracias.
Se podrían generar solo 2 columnas de n umeros aleatorios y que la tercera fuera el residual. Pero el efecto sería el mismo: una R2 cercana a 1. Saludos!
Pingback: PREP III | Javier Aparicio dot net